
Were you searching for insights on how Inferencing as a Service is becoming the backbone of modern enterprise operations?
Inferencing as a Service (IaaS) represents the next evolutionary leap in artificial intelligence deployment, where businesses access AI model inference capabilities through cloud-based platforms rather than maintaining expensive on-premises infrastructure. This service-oriented approach to AI inference enables companies to harness the power of machine learning models for real-time decision-making without the complexity and cost of building and maintaining their own AI infrastructure.
Picture this: It’s 2026, and your competitor just launched a product that responds to customer queries in milliseconds, personalizes experiences in real-time, and predicts market trends with unprecedented accuracy. Meanwhile, your team is still waiting for budget approval to hire AI specialists. This isn’t science fiction—it’s the reality companies face when they ignore the Inferencing as a Service revolution.
Here’s the truth that’s keeping tech leaders awake at night:
The AI inference market is experiencing explosive growth. The AI Inference market is expected to grow from USD 106.15 billion in 2025 and is estimated to reach USD 254.98 billion by 2030; it is expected to grow at a Compound Annual Growth Rate (CAGR) of 19.2% from 2025 to 2030. More importantly, 78 percent of respondents say their organizations use AI in at least one business function, up from 72 percent in early 2024 and 55 percent a year earlier.
But here’s what’s really driving this transformation…

The landscape of enterprise technology is shifting beneath our feet. While everyone talks about training AI models, the real game-changer lies in inference—the process of using trained models to make real-time decisions, predictions, and recommendations.
Why does this matter for your business?
Traditional AI deployment requires massive upfront investments, specialized teams, and months of infrastructure setup. But Inferencing as a Service changes everything. It democratizes AI access, making enterprise-grade inference capabilities available to any organization, regardless of size or technical expertise.
And the numbers don’t lie:
The global AI inference market size was estimated at USD 97.24 billion in 2024 and is projected to grow at a CAGR of 17.5% from 2025 to 2030. This isn’t just growth—it’s a fundamental shift in how businesses operate.
Inferencing as a Service is a cloud-based model that provides on-demand access to AI inference capabilities without requiring organizations to build, maintain, or manage the underlying infrastructure. Think of it as the “Netflix of AI”—you get access to powerful AI models when you need them, how you need them, without owning the entire production studio.
Here’s how it works:
Instead of spending months setting up GPU clusters, hiring data scientists, and managing model deployment, companies can simply connect to inference APIs and start making AI-powered decisions immediately. The service provider handles all the heavy lifting—model hosting, scaling, optimization, and maintenance.
At its core, Inferencing as a Service consists of:
Let’s talk numbers, because they paint a clear picture of where we’re heading.
The inference market is experiencing unprecedented expansion:
But here’s what these numbers really mean:
Every percentage point of this growth represents thousands of companies making the transition to AI-powered operations.
The adoption curve is steepening rapidly:
“The companies that survive the next decade will be those that can adapt their decision-making to AI speed, not human speed.” – Tech industry analyst from Reddit discussion on AI transformation
Building AI inference capabilities in-house is like trying to build your own power plant instead of plugging into the electrical grid. Consider these challenges:
Cost Barriers:
Technical Challenges:
Time-to-Market Issues:
Here’s what successful companies are discovering:
Speed of Innovation: Companies using Inferencing as a Service can deploy new AI capabilities in days, not months. This agility becomes a competitive moat that’s difficult to overcome.
Resource Optimization: Instead of hiring expensive AI teams, businesses can redirect resources to core competencies while still accessing cutting-edge AI capabilities.
Risk Mitigation: Service providers handle model updates, security patches, and performance optimization, reducing the risk of AI implementation failures.
The math is simple—and compelling:
Companies getting a 3.7x ROI for every buck they invest in GenAI and related technologies. But here’s the kicker: this ROI is primarily achieved through service-based AI consumption, not in-house development.
Cost Comparison Analysis:
In-house Development:
Inferencing as a Service:
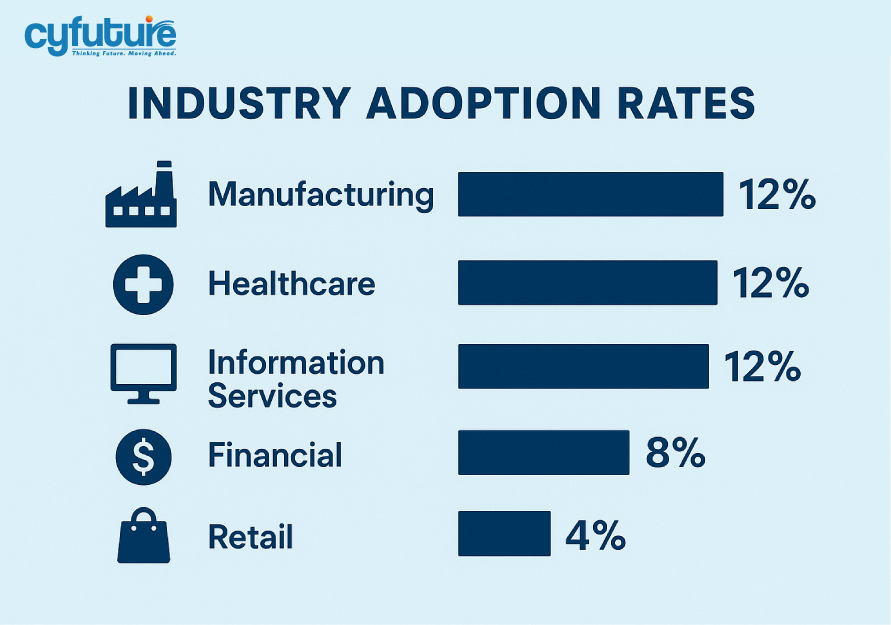
Healthcare organizations are leveraging Inferencing as a Service for:
Real-world Impact: Hospitals using inference services report 35% faster diagnostic times and 28% improvement in treatment outcome predictions.
Financial institutions deploy Inferencing as a Service for:
Market Impact: Information services companies report an AI adoption rate of about 12%, with inference services leading this adoption.
Manufacturers utilize inference services for:
Efficiency Gains: Companies report 25-40% reduction in unplanned downtime and 15-30% improvement in product quality metrics.
Retail organizations implement Inferencing as a Service for:
“We went from having a basic recommendation system to a world-class personalization engine in less than two weeks using inference APIs. The impact on our conversion rates was immediate and substantial.” – E-commerce CTO from Quora discussion
Modern Inferencing as a Service platforms deliver:
At Cyfuture, we’ve been at the forefront of cloud transformation for over a decade, helping enterprises navigate complex technology transitions. Our Inferencing as a Service solutions combine world-class infrastructure with deep domain expertise, ensuring your AI initiatives deliver measurable business value.
Why Cyfuture India?
Our clients have achieved remarkable results: average deployment times of just 3 days and ROI realization within the first quarter of implementation.
The Problem: Organizations worry about sending sensitive data to external inference services.
The Solution:
The Problem: Existing systems may not easily integrate with new inference APIs.
The Solution:
The Problem: Usage-based pricing can make budget planning difficult.
The Solution:
The Problem: Generic models may not perform optimally for specific use cases.
The Solution:
The next evolution combines cloud-based Inferencing as a Service with edge computing:
We’re seeing the emergence of:
Future platforms will feature:
As AI governance matures, expect:
Don’t try to “AI-ify” everything at once. Instead:
Remember: AI is only as good as the data you feed it.
Even if you’re starting small:
Technical implementation is only half the battle:
“The biggest mistake we see companies make is treating AI adoption as a technology problem instead of a business transformation challenge.” – AI consultant from LinkedIn discussion
Direct Cost Savings:
Revenue Enhancement:
Risk Reduction:
For a mid-sized company implementing Inferencing as a Service:
Costs (Annual):
Benefits (Annual):
Net ROI: 329% in the first year
The evidence is overwhelming: Inferencing as a Service isn’t just a trend—it’s the foundation of competitive advantage in the AI-driven economy. Companies that act now will lead their industries, while those who wait will spend years catching up.
The choice is yours:
Continue investing in complex, expensive AI infrastructure while your competitors gain market share with agile, scalable inference solutions—or join the leaders who are transforming their operations with Inferencing as a Service.
At Cyfuture India, we’ve helped over 500 enterprises successfully navigate their AI transformation journeys. Our battle-tested Inferencing as a Service platform combines cutting-edge technology with deep domain expertise, ensuring your success from day one.

Modern Inferencing as a Service platforms often provide superior security compared to in-house solutions. They employ enterprise-grade encryption, regular security audits, and compliance certifications. Additionally, they benefit from dedicated security teams and faster response to emerging threats than most organizations can maintain internally.
Reputable providers implement strict data handling policies. Your data is typically processed in real-time and not stored permanently. Many services offer options for data residency, encryption in transit and at rest, and even on-premises deployment for maximum control over sensitive information.
Professional Inferencing as a Service providers offer sophisticated model versioning systems. You can test new model versions in sandbox environments before production deployment, maintain multiple model versions simultaneously, and roll back to previous versions if needed.
Most organizations can deploy their first inference-powered application within 1-2 weeks. Complex integrations with existing systems may take 4-8 weeks, but this is still significantly faster than the 6-12 months required for in-house development.
Choose providers that offer compliance certifications relevant to your industry (HIPAA for healthcare, PCI DSS for payments, etc.). Many providers also offer detailed audit logs, data processing agreements, and compliance reporting features to support your regulatory requirements.
Yes, most Inferencing as a Service providers offer model fine-tuning services. You can provide your own training data to customize pre-trained models for your specific requirements while still benefiting from managed infrastructure and optimization.
Pricing typically follows a usage-based model (per API call or compute time). Most providers offer detailed usage analytics, spending alerts, and reserved capacity options for predictable workloads. This allows for better cost control compared to fixed infrastructure investments.
Enterprise-grade Inferencing as a Service providers offer built-in redundancy, geographic distribution, and automatic failover capabilities. This often provides better availability than organizations can achieve with in-house infrastructure, typically offering 99.9%+ uptime guarantees.
The beauty of Inferencing as a Service is that it requires minimal AI expertise. Your development team needs basic API integration skills, and you may want one person to understand AI concepts for optimization, but you don’t need specialized AI infrastructure teams.













